.jpg)
Learning Kalman Filter#
卡尔曼滤波的通俗解释#
卡尔曼滤波实际上解决了这样一个问题: 假设对某一个系统, 你有一个观测结果, 然后基于建模你也有一个预测结果,那么你很自然会想到要把这2个结果进行一个融合, 从而得到一个更靠谱的结果。 那怎么融合呢,最简答的可能是加权平均, 你可以根据经验觉得谁更靠谱就多信任谁一点, 那这个加权系数你就可以根据经验确定下来了。 实际中你确实可以这么做, 但是效果不见得好。 那卡尔曼滤波其实就是提出了一种更好的加权融合的方案, 它根据协方差(考虑单变量就是方差, 更便于理解)来决定谁更靠谱, 直观来说, 就是方差越小, 那么它就更靠谱(想象一下, 对高斯分布, 方差为0意味着什么, 意味着没有不确定性啊, 100%的肯定呀, 那当然靠谱了)。 并且这个加权系数是动态确定的, 那灵活性就更高了, 有时候观测值更靠谱, 有时候预测值更靠谱, 卡尔曼滤波都能适应这种情况。 更重要的是, 它还是有扎实的理论保证的, 保证让你的每次卡尔曼滤波的估计结果的方差都是小于观测方差和预测方差的, 从而就保证了卡尔曼滤波的方差是越来越小的。 这点同样很重要, 因为我们的卡尔曼滤波是一个迭代估计的过程, 这一点能保证卡尔曼滤波结果是朝着越来越好的方向房展的。 这也就是为什么卡尔曼滤波性能如此强大的关键原因, 随着迭代的进行, 卡尔曼滤波的结果会越来越好。
关于公式的得来, 这里也做一个通俗的解释:公式中最重要的一项是把观测结果和预测结果进行一个加权求和, 这从直观上很好理解, 但是其实背后是有严谨的数学理论支撑的。我们有一个观测, 有一个预测,那么我们最好的估计结果是什么呢?其实应该是在这2者共同的区间内, 代表这2个事件同时发生,那当然就更有把握说这个预测结果是更好的, 那这在数学上是什么呢? 是2个概率密度函数相乘呀。 如果2个过程都是高斯分布的话, 根据极大似然法, 很容易就推导出后验估计结果 以及方差。 它的后验估计结果形式刚好就是加权求和的形式。
至于滤波器这个名称,先来看一个简单的例子,低通滤波器,结果=低频信号×1+高频信号×0
所以卡尔曼滤波器做的工作也差不多,就是估计理想状态:结果=信号×1+噪声×0
适用范围#
高斯线性系统 - 线性系统:满足叠加性和齐次性 - 高斯系统:噪声满足正态分布
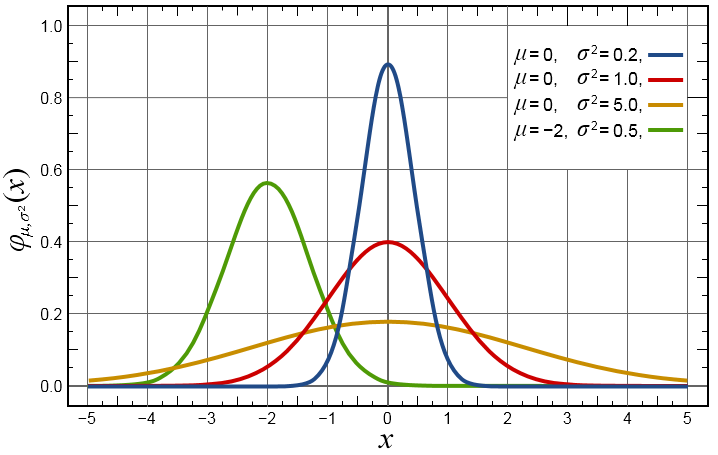
卡尔曼滤波的数学原理#
状态空间表达式#
状态方程:\(x_k = Ax_{k-1} + Bu_{k-1} + w_{k-1}\)
观测方程:\(z_k = Hx_k + v_k\)
其中,\(x_k\)是状态向量,\(x_{k-1}\)是上一时刻的状态向量,\(A\)是状态转移矩阵,\(B\)是控制矩阵,\(u_{k-1}\)是控制向量,\(w_k\)是状态噪声,\(z_k\)是观测向量,\(H\)是观测矩阵,\(v_k\)是观测噪声。
所以我们就是在用上一时刻的最优估计来预测这一时刻的状态(也叫做先验估计),然后用观测值来修正这个预测值,得到这一时刻的最优估计(也叫做后验估计)。
放到一个一维的例子中,状态方程可以写成:\(x_k = ax_{k-1} + bu_{k-1} + w_{k-1}\)
观测方程可以写成:\(z_k = hx_k + v_k\)
以一个带温度计保温杯为例,要观测的是温度
因为保温,所以温度不变,及状态转移矩阵(一维就是一个数)为1,没有其他控制因素,所以控制矩阵为0。当然因为保温杯的保温效果不是完美的,所以有一个状态噪声。
所以状态方程可以写成:\(x_k = x_{k-1} + w_{k-1}\)
从温度计上读到的温度就是温度,所以观测矩阵(一维就是一个数)为1,当然温度计也有误差,所以有一个观测噪声。
所以观测方程可以写成:\(z_k = x_k + v_k\)
注意,\(v_k\)和\(w_k\)都是高斯分布的,且相互独立,他们分别服从
\(w_k \sim N(0, Q)\)
\(v_k \sim N(0, R)\)
对于一维的例子,\(Q\)和\(R\)都是一个数,分别代表状态噪声和观测噪声的方差。对于多维的情况,\(Q\)和\(R\)是协方差矩阵,分别代表状态噪声和观测噪声的协方差矩阵。
其中的Q,R分别是状态噪声和观测噪声的协方差矩阵,这个是需要事先给出的。一般是通过经验值得到,也就是这个系统的超参数。对于传感器的噪声,可以通过标定得到。
以上,构成了这个系统的状态空间表达式。状态空间表达法就是将系统用一组输入、输出及其之间的关系进行表征的方法。他们之间的关系通过一阶微分方程描述。
卡尔曼滤波的工作流程(套公式)#
预测
通过上一时刻的最优估计来预测这一时刻的状态(也叫做先验估计)
\(x_k^- = Ax_{k-1} + Bu_{k-1}\)
\(P_k^- = AP_{k-1}A^T + Q\)
其中,\(x_k^-\)是先验估计,\(P_k^-\)是先验估计的协方差矩阵。
更新
用观测值来修正这个预测值,得到这一时刻的最优估计(也叫做后验估计)
\(K_k = P_k^-H^T(HP_k^-H^T + R)^{-1}\)
\(x_k = x_k^- + K_k(z_k - Hx_k^-)\)
\(P_k = (I - K_kH)P_k^-\)
其中,\(K_k\)是卡尔曼增益,\(x_k\)是后验估计,\(P_k\)是后验估计的协方差矩阵。
卡尔曼增益的作用是根据先验估计的不确定性和观测的不确定性来决定对先验估计的修正程度。当观测的不确定性越大,卡尔曼增益越小,对先验估计的修正程度越小。当观测的不确定性越小,卡尔曼增益越大,对先验估计的修正程度越大。
从公式上看,卡尔曼增益是由先验估计的不确定性和观测的不确定性来决定的,这也是卡尔曼滤波的核心思想。
【附】数学知识#
变式#
EKF#
卡尔曼滤波的前提是系统的状态改变和观测是线性的,但是实际应用中系统是非线性的。EKF通过一个一阶泰勒展开的线性系统来近似非线性。
UKF#
ESKF#
Partical Filter#
优化和滤波#
卡尔曼滤波器: 从k-1时刻后验推k时刻先验,从k时刻先验推k时刻后验 (马尔可夫假设)
扩展卡尔曼滤波器:对卡尔曼滤波器进行修正,针对不是线性的情况,采用一阶泰勒展开近似线性(马尔可夫假设) ;
BA优化:把一路上的所有坐标点(像素坐标对应的空间点等)与位姿整体放在一起作为自变量进行非线性优化
PoseGraph优化: 先通过一路递推方式算出的各点位姿,通过数学方式计算得到一个位姿的变换A,再通过单独拿出两张图像来算出一个位姿变换B,争取让B=A
增量因子图优化:保留中间结果,每加入一个点,对不需要重新计算的就直接用之前的中间结果,需要重新计算的再去计算,从而避免几余计算。iSAM是增量的处理后端优化。由于机器人是运动的,不同的边和节点会被不断加入图中。每加入一个点,普通图优化是对整个图进行优化,所以比较麻烦和耗时。iSAM的话相当于是保留中间结果,每加入一个点,对不需要重新计算的就直接用之前的中间结果,对需要重新计算的再去计算。以这种方式加速计算,避免元余计算。
从全文的整理来看,特别是在IKF章节,我们可以发现滤波算法其实就是将Sliding Window的大小设置为1的优化算法,不论是优化算法还是滤波算法都是期望求解出问题概率模型的最大似然估计 (MLE),本质上滤波就是基于马尔可夫假设将优化问题的建模进行了“特征化”的处理。
再进一步分析,正因为滤波器进行了范围上维度的“简化”、模型的近似处理,所以其计算消耗较于优化算法更低,但由此引发的代价就是精度上的损失。
另一个需要考虑的方面是,滤波器是由先验信息+运动模型+观测信息三个方面点顺序执行,以实现位姿状及其协方差的估计和更新,也正因为滤波器的框架如此,若是先验(上一时刻)状态出现了问题,比如位姿跟丢、计算错误等,那么在该时刻之后的状态都会出现问题以致纠正不回来了,而基于优化方法的位姿求解则会考虑更多时刻 (关键) 下的状态信息和观测信息,即使有某一时刻的状态量和协方差是outlier,系统也有一定的能力维稳。
如果在处理器算力充足且精度为第一需求的前提下,那么在位姿估算问题处理上是首推优化算法,但若是效率是第一前提条件,那么就需要根据实际的应用情况和机器人问题模型选择合适的滤波器了。