.jpg)
点云匹配算法#
RANSAC算法(随机抽样一致性)#
粗配准
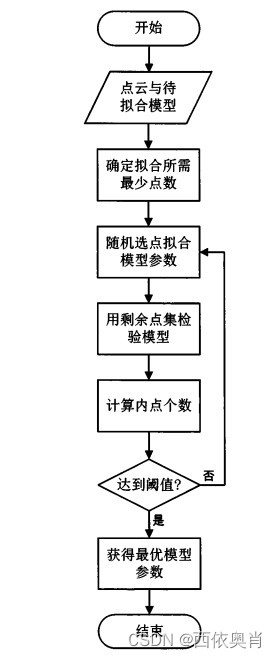
使用 RANSAC 的方法,总而言之就是对于源点云中的三个点,去“蒙”他们和目标点云中的那几个点相对应,然后计算变换矩阵,检验其优劣。简要流程如下:
在源点云中随机选择 3 个点。
分别查找他们在目标点云中特征向量最接近的点。这里的“接近”是欧式距离意义下的,查询数据结构使用 KD 树。
计算两个三角形之间的变换矩阵。其实就是按照 ICP 精配准的过程,求最小二乘法意义下的最优变换矩阵。
求出源点云在此变换之后的点云,计算其与目标点云的重合度(定义为源点云中阈值半径内存在目标点的点的个数)。
回到1,重复若干次,维护并返回重合度最高的变换。
实际编码中,由于 4 中 KD 树查询速度比较慢(33 维空间中接近于 O ( n ) O(n)O(n)),因提高在 1、2 中选择三角形对的质量是一个好的做法。这里三角形对的质量一是指他们匹配的可能性,二是通过他们计算出的变换矩阵是否准确。可以想到的方法有很多,比如三角形的边不能太短、两个三角形的对应边长不能差太多、优先选择特征向量远离均值的点等等。我的实现中采用了前两种。此外,在降采样后的点云上配准也可以提高效率。
算法流程:
SAC-IA算法(采样一致性)#
粗配准
该算法的总体思路如下:
将需要配准的目标点云P中选择n个采样点。为了保证所选取的采样点尽可能有不同的FPFH特征,采样点的距离一般要选择的恰当,尽可能分散,一般要大于预定的最小距离d;
在模板点云Q中查找与目标点云P中具有相似FPFH特征的对应点,这些点可能是一个或多个,但是从这些点中选取一个作为最终的对应点。
根据以上步骤得到对应点集,计算目标点云和模板点云之间的刚性变换矩阵,同时计算出配准后的误差,以及点云配准后的质量。
重复以上三个步骤,找到误差和最小的变换,然后用于点云的粗配准。 文献通过查找大量不同的对应点集,快速找到良好的转换关系。采用Huber惩罚函数来确定最小误差和。
解决点云数据之间的初始对齐问题
基本可以实现角度上的对齐
基于采样一致性的方法,通过迭代的方式找到最优的平面模型
ICP algorithm#
算法步骤#
定义代价函数
代价函数就是经过transform后的source点云$vec{S}$和target点云$vec{Q}$之间所有对应点之间的欧氏距离。
实现上,首先计算两个点云的几何中心,并将两个点云平移到原点,这样可以简化代价函数,这样需要找到的使得代价函数最小的transform就只有旋转矩阵R。T的求解方法是$T=vec{Q}-Rvec{S}^T$
寻找对应点
为了加速计算,我们不需要计算 Target 点云中每个点到 Source 点云中一点的距离。可以设定一个阈值,当距离小于阈值时,就将其作为对应点。
甚至不需要两个点集中的所有点。可以指用从某一点集中选取一部分点,一般称这些点为 控制点(Control Points)
优化
ICP的优化基于最小二乘法,通过最小化代价函数来求解最优的旋转矩阵R。
收敛条件
检查是否达到收敛条件,如,迭代次数达到上限,或者两次迭代之间的误差小于某个阈值。
如果没有达到收敛条件,就回到第二步,重新计算对应点,然后再次优化。否则,就认为找到了最优的旋转矩阵R。就可以将 Source 点云通过 R 进行旋转,然后再平移,就可以得到两个点云之间的最优对齐。算法结束。
PCL中的ICP参数#
{'solver_euclidean_fitness_epsilon':1e-5},
{'solver_transformation_epsilon':1e-5},
{'solver_max_correspondence_distance':2.0},
{'solver_correspondence_randomness':20},
{'solver_max_optimizer_iterations':20},
{'solver_use_reciprocal_correspondences':True},
{'solver_use_trimmed':True},
{'solver_use_point_to_plane':True},
{'solver_point_to_plane_weight':1.0},
{'solver_point_to_point_weight':1.0},
NDT algorithm(Normal Distributions Transform)#
似乎就在ICP中间加上几步,一个是将点云数据分割成相等的格子,然后用Normal Distribution来描述每个格子的点云数据,然后再用ICP来进行配准。但计算的不是点云之间的距离,而是点云之间的概率分布。
NDT算法主要分为两步:NDT建图和NDT匹配。在NDT建图阶段,算法将一个点云转换为高斯分布函数,并将其存储为一个栅格地图。在NDT匹配阶段,算法将两个点云都转换为高斯分布函数,并使用最小化KL散度的方法来找到它们之间的最佳匹配。与ICP算法相比,NDT算法具有更高的配准精度和鲁棒性,尤其是在噪声和不规则形状的情况下。然而,NDT算法的计算量相对较大,需要较长的处理时间。
KL散度:
KL散度(Kullback-Leibler Divergence)是一种用于度量两个概率分布之间差异的非对称性度量。它通常用于度量一个概率分布(真实分布)与另一个概率分布(拟合分布)之间的差异。KL散度的定义为:
其中,P(X) 是真实分布,Q(X) 是拟合分布。KL散度满足非负性,即当且仅当 P(X)=Q(X) 时,KL散度为0。KL散度不满足对称性,即 KL[P(X)||Q(X)]≠KL[Q(X)||P(X)]。
点云匹配算法比较#
算法 |
基本思想 |
优化目标 |
改进 |
优点 |
缺点 |
|---|---|---|---|---|---|
ICP |
使用点到点的距离作为误差;通过迭代求解的方法缩小误差,得到使误差方程最小的旋转矩阵R和平移矩阵t。 |
\(E(R, t)=\frac{1}{N_{p}} \sum_{i=1}^{N_{p}}\left|x_{i}-R p_{i}-t\right|^{2}\) |
— |
简单、直观 |
容易陷入局部最优解、对初始值敏感、收敛速度慢、精度低;两帧激光点云数据中的点不可能表示的是空间中相同的位置。所以用点到点的距离作为误差方程势必会引入随机误差。 |
PL-ICP |
采用点到其最近两个点连线的距离作为误差方程。 |
\(J(\boldsymbol{q}_{k+1},\boldsymbol{C}_k)=\sum_i\left(\boldsymbol{n}_i^\mathrm{T}\left[\mathbf{R}(\theta_{k+1})\boldsymbol{p}_i+\boldsymbol{t}_{k+1}-\boldsymbol{p}_{j_1^i}\right]\right)^2\) |
相对于PP-ICP最大的区别是其改进了误差方程, PP-ICP是点对点的距离作为误差而PL-ICP是采用点到其最近两个点连线的距离 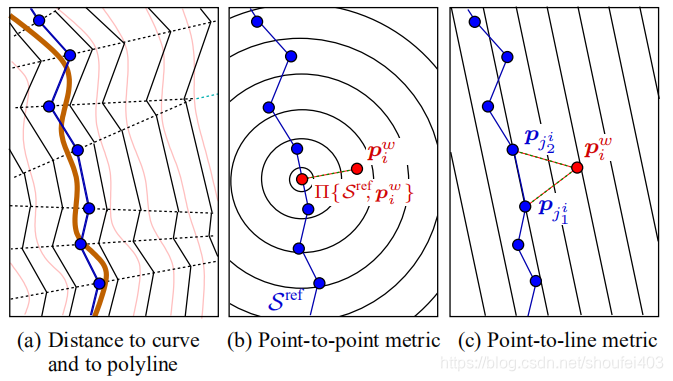
|
1)误差函数的形式不同,ICP对点对点的距离作为误差,PL-ICP为点到线的距离作为误差,PL-ICP的误差形式更符合实际情况;2)收敛速度不同,ICP为一阶收敛,PL-ICP为二阶收敛 \(∥q_k − q_∞ ∥ < c ∥ q_{k−1} −q_∞∥\) \(∥q_k−q_∞ ∥^2 < c ∥ q_{k−1}−q_∞∥^2\);3)PL-ICP的求解精度高于ICP,特别是在结构化环境中。 |
对初始值更敏感、容易陷入局部循环 |
NICP |
主要流程和思想和ICP一致 |
在Trim outlier和误差项里考虑了更多的因素,这也是它效果更好的原因:1)由于在寻找点匹配的过程中,考虑了环境 曲面的法向量和曲率,因此可以提前排除 一些明显是错误的匹配。这样就减少了计算量并且提高了计算结果的精度。2)在误差定义中,除了考虑欧式距离之外,还考虑了法向量之间的夹角,因此具有更加准确的求解角度。3)用LM方法进行迭代求解目标误差方程,迭代收敛即可得到两帧激光数据之间的相对位姿。 |
精度高、对初始值不敏感、收敛速度快 |
||
IMLS-ICP |
1)选择具有代表性的激光点来进行匹配,既能减少计算量同时又能减少激光点分布不均匀导致的计算结果出现偏移。2)点云中隐藏着真实的曲面,最好的做法是能从参考帧点云中把曲面重建出来。3)曲面重建的越准确,对真实世界描述越准确,匹配的精度就越高。 |
IMLS-ICP使用高斯拟合和最小二乘重建出一个隐含的曲面。找到空间点在隐含曲面的投影点。使用点到该曲面上投影点间的距离构建误差方程。 |
对噪声和离群点具有鲁棒性、精度高 |
计算量大、复杂度高 |
|
NDT |
normal distribution transformation正态分布变换!该算法的核心思想是首先将空间离散为方格,若是二维空间,则离散为栅格,若是三维空间则离散划分为立方体,这样就可以将采样的点云划分到不同的网格中,这样可以很方便的描述点云的局部特性,例如点云局部的形状(直线、平面or球体)、方向(平面法向、直线方向等)。现在我们可以利用统计的方法分析每一个网格的特性。 
|
\(Likelihood: \Theta=\prod_{k=1}^nf(T(\vec{p},\vec{x}_k))\) |
利用统计的方法 |
配准过程中不利用对应点的特征计算和匹配,所以有可能比其他方法快 |